")

Enterprise Information Systems and IT services
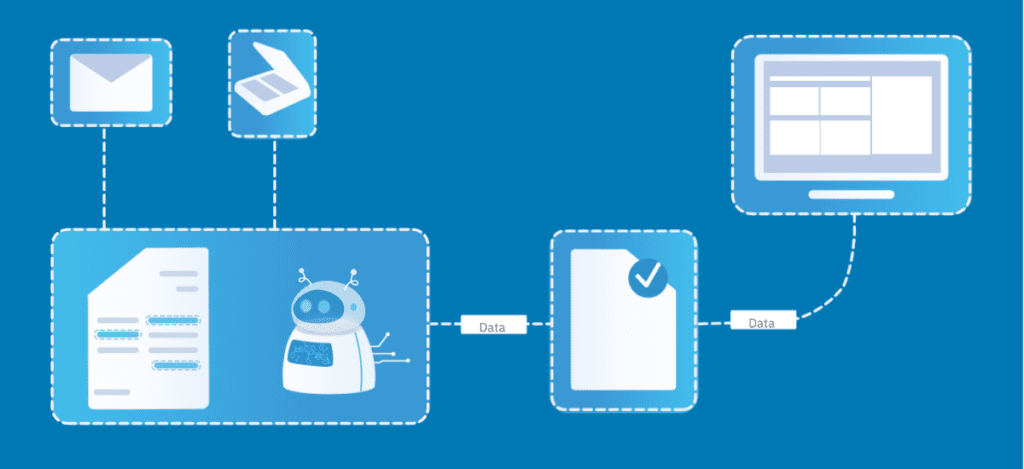
Optical Character Recognition (OCR) tools make it possible to convert non-searchable PDF documents and scanned image files into searchable formats. They support zonal data extraction as well as barcode and QR code recognition.
Modern intelligent data extraction systems help businesses quickly and easily digitize their documents and automate the extraction of necessary information – all with minimal error rates!
The use of OCR is now essential in many areas – from document archiving and administrative automation to improving data accessibility. Today’s advanced OCR technologies also leverage machine learning, enabling them to efficiently handle document structures, various font types, and even damaged or poorly legible text.
The systems independently extract data from scanned and electronic documents (such as invoices, purchase orders, delivery notes, and other structured or semi-structured documents), validate the data, and store it in your desired enterprise system, such as an ERP or DMS, where further internal processes can be triggered immediately.
By automating data extraction, you eliminate many errors typically caused by manual document processing. The data is checked against predefined rules and can be compared with other data sources, such as ERP or CRM master data. Over time, the need for manual intervention is reduced to an absolute minimum, as the systems continuously learn thanks to built-in artificial intelligence.
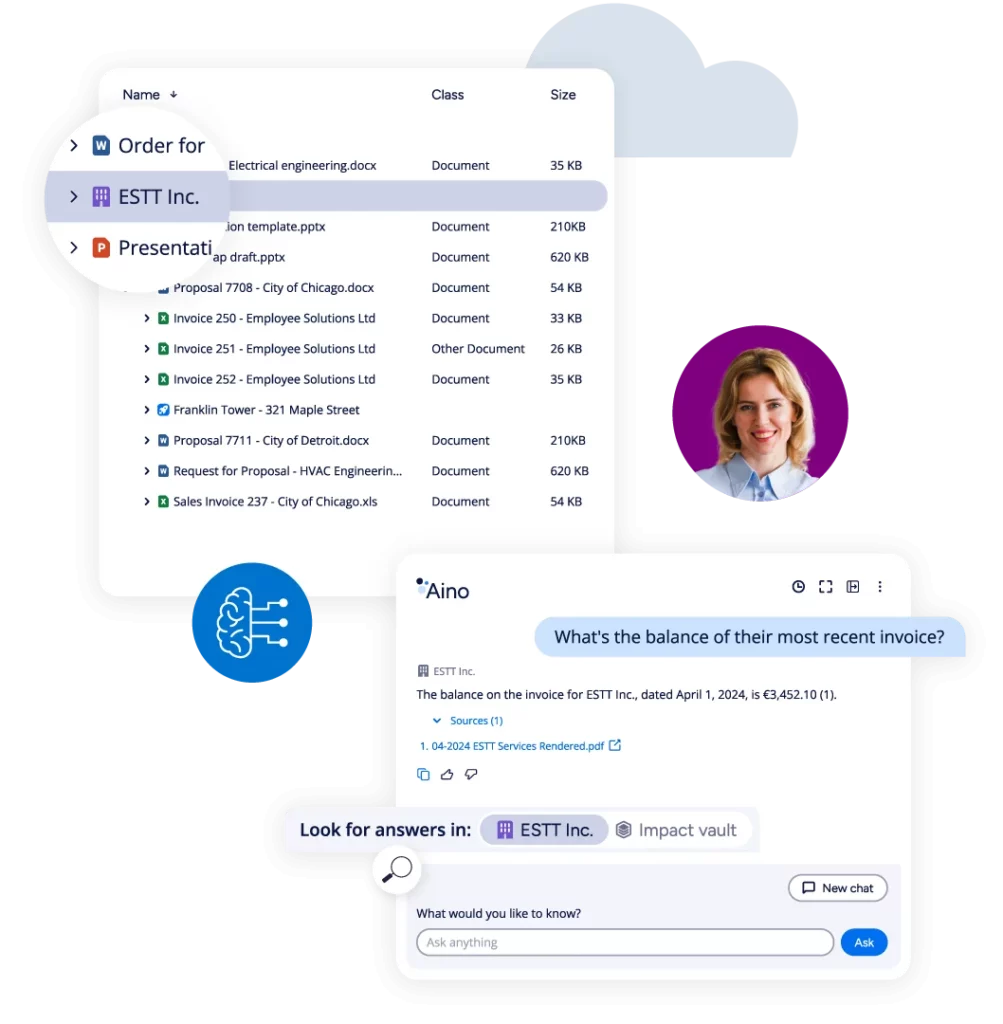
M-Files Aino is an artificial intelligence integrated directly into the M-Files system, designed to help users find exactly what they’re looking for and work more efficiently. Its biggest advantage is the ability to extract data from documents, which can then be further processed and stored directly within the M-Files system.
Aino also allows users to ask questions based on their data, summarize documents, or translate content into other languages. Accurate metadata ensures greater precision, correct classification, and faster search results.
DOCU-X is a standalone tool for automated document data extraction. One of its key advantages is the automatic validation of both extracted and manually entered data, with error values clearly highlighted. The data is checked according to predefined rules and can also be compared with other data sources.
The DOCU-X OCR system can be easily integrated with various enterprise systems, such as the Helios ERP system or the M-Files DMS system.
At PETROF, spol. s r.o., the largest manufacturer of acoustic pianos in Europe, we implemented a solution combining M-Files and DOCU-X OCR. This allowed the company to simplify and automate the lifecycle of incoming invoices, from receipt to approval. Incoming invoices now automatically enter the DOCU-X OCR system, where all necessary data is extracted. The invoices are then automatically transferred to the M-Files system, where an approval workflow is triggered based on the invoice type.
If you’re interested in the full case study, you can read it here.
If you’re looking for a solution to streamline document search and handling, get in touch with us – together, we’ll find the right solution for you!
| Cookie | Duration | Description |
|---|---|---|
| cli_user_preference | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store information about the user's consent to the use of cookies. It does not store any personal data. |
| cookielawinfo-checkbox-advertisement | 11 months | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category. |
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by the GDPR Cookie Consent plugin to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 1 Year | Set by the GDPR Cookie Consent plugin to store the user consent for cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| CookieLawInfoConsent | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store information on whether or not the user has agreed to the use of cookies. |
| pll_language | 1 Year | The pll _language cookie is used by Polylang to remember the language selected by the user when returning to the website, and also to get the language information when not available in another way. |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
| Cookie | Duration | Description |
|---|---|---|
| _GRECAPTCHA | 11 months | This cookie is used by the Google ReCaptcha service to protect forms against spam. |
| Cookie | Duration | Description |
|---|---|---|
| _ga | 2 Years | The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors. |
| _gat_gtag_UA_363327_1 | 1 minute | Set by Google to distinguish users. |
| _gid | 1 day | Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously. |
| _sp_id.6602 | 2 Years | The _sp_id.52eb cookie is used to analyze the user behavior on the website. |
| _sp_ses.6602 | 30 minutes | The _sp_ses.6602 cookie is used to analyze the user behavior on the website. |
| 2-2bb287d15897fe2f9d89c882af9a3a8bwww.digres.czecwshown | 11 months | The 2-2bb287d15897fe2f9d89c882af9a3a8bwww.digres.czecwshown cookie is used to collect information and analyze user behavior on the site. |
| CONSENT | 2 Years | YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data. |
| ecsession2-2bb287d15897fe2f9d89c882af9a3a8b | 11 months | The ecsession2-2bb287d15897fe2f9d89c882af9a3a8b cookie is used to collect information and analyze user behavior on the site. |
| ecvisits2-2bb287d15897fe2f9d89c882af9a3a8b | 11 months | The ecvisits2-2bb287d15897fe2f9d89c882af9a3a8b cookie is used to collect information and analyze user behavior on the site. |
| VISITOR_INFO1_LIVE | 5 months | A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface. |
| Cookie | Duration | Description |
|---|---|---|
| YSC | session | YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages. |
| yt-remote-connected-devices | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt-remote-device-id | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |